软件方法(下)分析和设计 第8章 分析类图
您在阅读《软件方法》时如果发现错误,欢迎通过微信umlchina2告知。如果作者认为有道理,决定在下一次发布时根据您的意见修改,将付给您5.12元报酬,并在书中说明您的贡献。报酬通过微信支付。
(1)任何您认为的错误都可以,包括错别字。
(2)同一错误仅支付最先指正者报酬。
(3)请根据最新版本作指正。
下册内容目前指正人有(按指正时间排序):吴佰钊、王周文、刘学斌、成文华、黄树成、李蜀斌、杨雪鸿、王书伟、高洪江、张志坚。
墙上挂了根长藤,长藤上面挂铜铃
《长藤挂铜铃》;词:元庸,曲:梅翁(姚敏),唱:逸敏,1959
8.1 分析工作流概述
8.1.1 知识的分离
在业务建模和需求工作流,我们一直把目标系统看作是一个整体,想办法推导出涉众在意的整体表现——需求。
系统为了满足需求,必须封装一定的知识。这些知识,没法从天上掉下来,需要软件开发人员一点一点放进去。接下来,我们将思考:
(1)如何准确表达系统需要封装的知识,让系统满足需求;
以及进一步
(2)如何合理组织系统需要封装的知识,低成本地让系统满足需求。
如果不能合理组织知识,当新需求到来时,准确表达也会越来越难。如果考虑到利润,很难停留在(1)而不追求(2)。
不管是纯粹在大脑里面打转转,还是借助了纸笔或建模工具来协助,以上的思考是逃不掉的。如果需要封装的逻辑很简单,人脑的容量和运算速度能够胜任,在大脑里打转转可以勉强应付。不过,能带来利润的系统都是复杂的(参见《软件方法(上)》1.8.1市场没有小系统),借助纸笔或建模工具来显式表达思考的过程很有必要,毕竟大脑容量和运算速度比一般人高出一个数量级的天才是很稀罕的。
有的人故意不显式表达,声称“大脑思考就够了”,背后的真相可能不是天才而是遮羞——你让他显式表达,他也表达不出来,因为没有掌握思考的方法。
思考的方法,也就是知识分离的方法,包括域和域之间的知识分离,以及域内部的知识分离。
8.1.2 核心域和非核心域
一个软件系统封装了若干领域的知识,其中一个领域的知识是系统不能抛弃或替换的,这个领域称为"核心域",其他领域称为"非核心域"。
图8-1展示了不同系统类型的核心域和非核心域概念:

图8-1 不同系统类型的核心域、非核心域概念
以文档处理器为例,开发Microsoft Word和LibreOffice Writer所使用的编程语言和组件不一样,但文档、页、行、字等核心域概念是一样的。即使回到计算机诞生之前或者去到未来,这些概念也依然存在。
关于“核心域”和“非核心域”,一种常用的通俗说法是"业务"和"技术",但"业务"和"技术"的说法并不严谨。
有的开发人员在潜意识里是这样划分的:
*我懂且我感兴趣的知识→技术;(我懂Java编码,我对Java编码感兴趣,Java编码是技术)
*我懂但不感兴趣的知识→业务;(下单、收银、配送我懂一些,但不感兴趣,这些是业务)
*我不懂但感兴趣的知识→高科技;(我不懂深度学习,但很感兴趣,哇塞,高科技)
*我不懂且不感兴趣的东东→忽悠。(我不懂UML建模,也不感兴趣,妈的,忽悠)
有的开发人员则是这样划分的:
*和计算机无关→业务;
*和计算机有关→技术;
核心域不能以“懂”、“感兴趣”来判断。核心域不一定是非计算机领域,也可以是计算机领域,如图8-1中的操作系统。
另外,还要特地说明的是,本书中的“核心域”和Eric Evans《领域驱动设计》以及后续相关书籍中的“核心域”(Core Domain)意思不同。
本书中的“核心域”指软件系统中不可替换的那部分内容——这个以软件开发人员的知识是可以判断的。
Eric Evans《领域驱动设计》知识体系中,把“领域”(相当于本书中的“核心域”)划分为"核心域"、“通用子域”、“支撑子域”等,例如“Delivery”是核心,“Customer”是通用,“Billing”是支撑——这个划分已经超出了软件开发人员的知识,我不认为软件开发人员有能力以及有必要做这样的判断。
商业竞争是另外一门学问。一家商场之所以能击败其他对手,原因未必是下单部分有什么不同,倒有可能是在配送环节下了大力气,或者客户服务抓得好。武断地认为某个子领域是“核心”是不合适的。
8.1.3 域之间的映射和协作
域和域之间的映射以及协作的规律,与域中的个体不直接相关。
例如,我们看一个"人员管理"领域的类图,如图8-2所示。

图8-2 核心域类图
如果将图8-2中的Person类映射为C#实现,可能会得到图8-3的C#代码:

图8-3 类的C#实现(用Enterprise Architect映射)
如果将图8-2中的类映射到关系数据库,会得到图8-4所示的数据库结构:

图8-4 将类图映射到数据库模型(用Enterprise Architect映射)
如果采用某种对象-关系映射器框架(例如微软的Entity Framework),Person对象和数据库中的Person表里的一行可能会这样联系起来:
person1=context.Persons.Find(ID)
如果将以上内容中的Person改成Dog,City改成Cat,映射的套路没有变化。如果我们调整了域之间的映射和协作的套路,得到的结果也会按照我们的调整有规律地变化,与域中的个体依然无关。
平时我们看到的一些“架构”,就是域之间映射和协作的一些套路。图8-5是现在常被提起的一些“架构”,可能在不同领域的系统中都会观察得到。
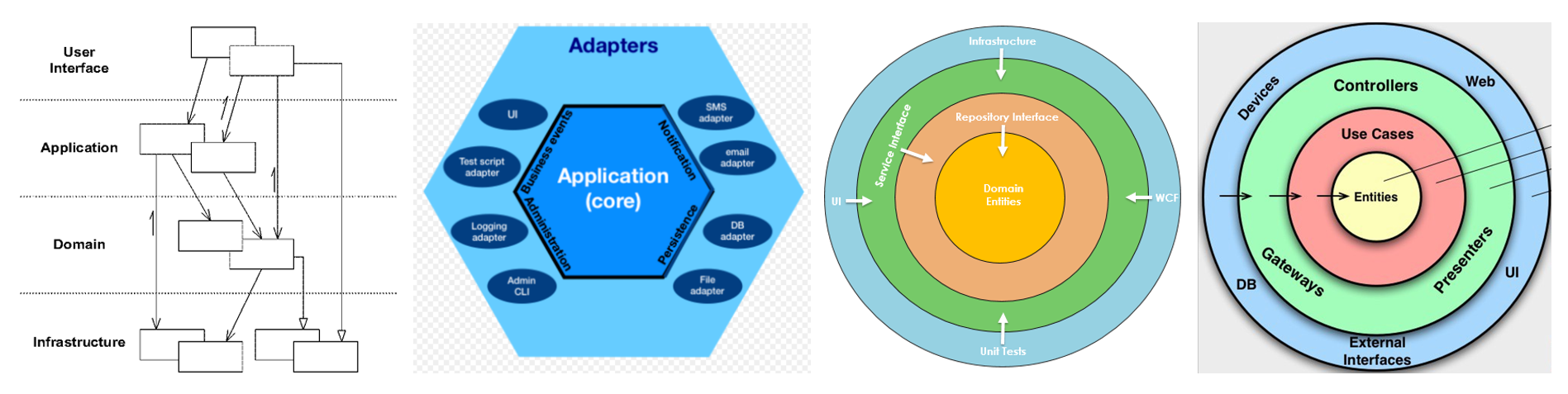
图8-5 一些常见的“架构”
既然域之间的映射有“套路”,过早地混合不同域的知识是不划算的。如图8-6所示,假设三个域要考虑的因素分别是a、b、c个,如果分开考虑,然后再找到域和域之间映射的规律,负担最小可以变成a+b+c;如果混在一起考虑,大脑的负担最大会达到a×b×c。a、b、c都大于√3时,相乘肯定要大于相加的。

图8-6 过早混合不同域的知识会增加大脑负担
过早地混合不同域的知识,会加重开发人员大脑的负担,导致开发人员腾不出脑力来思考核心域中更深刻的问题,只好稍微折腾一下如图8-5的“域之间的架构”,心里安慰自己,我有“架构”了!却忘了,其实还没有触碰到最需要大脑去思考的核心域概念和逻辑。而这又很可能会被巧妙地当成遮羞布——不是我不思考,而是要想的事情太多了顾不过来啊!
而这种微妙心态的进一步发展,就会导致开发人员有意无意地混合不同域的知识,把复杂度弄成a×b×c,以此达到通过废话刷工作量——以最少的思考得到最多的“成果”。
我经常听软件组织的架构师向我介绍他们所开发系统的“架构”,口沫横飞,说的基本上都是图8-5的“域之间的架构”。好啊,真棒,我知道了。还有呢?没了?
构思那些“域之间的架构”是某些厂商或者方法学家的工作,我们挑一个适合自己项目的套路用上就行了。有什么问题,可以去请教用这个套路用得好的先行者。
“域内部的架构”,那些核心域概念和复杂逻辑,这是系统最值钱的地方。要是我们没有办法理清楚,别人是帮不到我们的。这才是大脑最该用的地方!
平时我们说“需求变了”,大多数情况是功能需求变化,导致系统所封装的核心域逻辑需要调整,而不是“域之间的架构”需要调整,所以没有必要整天津津乐道“域之间的架构”。
一些以“领域驱动设计”为名的文章,所举例子就1-2个领域类,然后就开始讨论Entity、Service、Repository、DTO、六边形架构……不是说这个知识没用,问题是软件组织缺的是这个嘛?
*调查:您看过的以“领域驱动设计”为名的文章,里面有几个领域类?欢迎在本文下留言。*
在一些软件开发技术大会常可以看到这样的场景:某电子商务网站的架构师上台讲了一通,接着某视频网站的架构师上台也讲了一通,咦,两个演讲内容如此相似?原来,他们讲的都是自己系统中“域之间的架构”,而不是核心域内部的机制。究其原因也许并非不为,而是不能——架构师对自己所开发系统的核心域研究太浅。
许多“网红程序员 ”在网上谈论的内容大多是某种语言或框架的新特性,少有探讨他当前所开发系统的复杂领域逻辑,也是同样的原因:并非不为,而是不能。
说了那么多,归纳起来就是一句话:
8.1.4 重视分析工作流
分析,就是从核心域的视角构思系统的内部机理。
在现在的很多软件组织中,分析工作流的技能是非常被忽视的。很多开发人员上手就直接编码,原因并不是软件开发项目的领域逻辑简单到了不需要分析的地步,或者他在大脑里就完成了分析的工作,而是开发人员缺乏分析的技能,只好瞎碰了事,而且为了遮掩自己的无能,还会想各种办法来遮羞。
就像高考的时候,前面几道题比较容易,可以扫一眼就写答案。越往后题目越来越难,学霸会拿出草稿纸,列出已知条件,正推、逆推……理出解题思路,然后再答。
学渣就麻烦了,根本没有学习相关的知识和解题方法,怎么办?
遮羞利器(1):时间。
例如,抱怨考试时间太紧张,来不及思考,只好胡乱写个答案,甚至故意提前交卷,力图给人造成一种“如果时间允许,我是能做对的”的印象——真相是,给再多的时间也不会。
对应到软件开发,就是以“时间紧”、“敏捷”为借口掩盖自己没有能力剖析复杂逻辑的事实。
遮羞利器(2):空间。
例如,考试时故意选择不好写的笔和劣质的草稿纸,力图给人造成一种“如果纸和笔再好一点,我是能做对的”的印象——真相是,不会就是不会,给他再好的纸笔也不会。
对应到软件开发,就是借助“口头交流”、“白板”等容量小的介质,掩盖内容的苍白。白板就这么大,所以客观上你总不好意思让我用白板剖析复杂的逻辑吧?
伽罗瓦在决斗前一天晚上仓促写下自己的数学思想,不停哀叹“我没有时间了”。唉,早干嘛去了,不过伽罗瓦是真懂。

图8-7 伽罗瓦决斗前一天的手书
费马在书的空白处写下“费马猜想”,还写“我确信我发现一种美妙的证法,可惜这里的空白处太小,写不下”,估计费马是忽悠。
此处提到此二人纯属作者关于“时间”、“空间”不够的随意联想,无其他含义。
遮羞利器(3)听起来就比较高大上了:重构。
上世纪80年代末,Bill Opdyke(http://laputan.org/pub/papers/opdyke-thesis.pdf)和Bill Griswold(https://cseweb.ucsd.edu/~wgg/Abstracts/gristhesis.pdf)等人归纳了一些调整软件结构的手法,称为“重构”,后经Martin Fowler等人推广而广为流传。有的开发人员以此为借口逃避思考——“我先写快而脏的代码,然后再重构”。
其实,如果开发人员真的熟练掌握重构的手法,很多时候他完全可以建模领域逻辑,直接得到更合理的结构,根本不需要先走很多弯路再回正路,因为很多知识是共通的。要是开发人员以“重构”为理由拒绝思考,很可能他的“重构”也是空话。
摸着石头过河是难免的,但应该在不得不摸的时候才摸,不应该假装看不见已有的路和桥,无论大小事都主动追求摸着石头过河,而且,很多人不是假装看不见路,而是真的看不见路——就是个睁眼瞎。
当然,睁眼瞎也有好处。大脑不用思考,凭感觉摸着石头过河不停刷工作量,也是一种幸福。
8.1.5 分析相关历史的简单回顾
1958年,John W. Young Jr.和Henry K. Kent发表“Abstract formulation of data processing problems”,第一次提出在独立于实现的抽象级别上定义系统的规范。

图8-8 来自 “An abstract formulation of data processing problems”(Young JW, Kent HK,1958)的截图
1959年,CODASYL(数据系统语言会议)成立。1962年,CODASYL提出了一个和Young/Kent类似的模型,称为“信息代数”(Information Algebra)。
1970-1980年代是结构化分析方法的时代,主要贡献者有Börje Langefors、Chris Gane、Trish Sarson、Tom DeMarco、Pin-Shan Chen、E. F. Codd等人。结构化分析的主要建模方法是数据流图和实体-关系图,这两者的结合,让软件开发人员有能力剖析大型系统。

图8-9 来自 Structured analysis and system specification(DeMarco T,1979)的截图

图8-10 来自 The Entity–Relationship model: Towards a unified view of data(Chen PPS,1976)的截图
1982年,Nastec公司开发出了DesignAid,这是第一款CASE(计算机辅助软件工程)工具。随后,其他CASE工具陆续出现。据PC Magazine的1990年1月30刊统计,当时已经有超过100家公司提供了将近200款CASE工具。



图8-11 来自PC Magazine 1990年1月30日刊的截图(被圈住的内容说明了工具的数量)
1980年代后期,面向对象的思想开始用于分析和设计。然后,UML统一了表示法。这部分历史已经在本书第1章“UML简史”部分讲述,此处不再赘述。

图8-12 来自 Object Oriented Analysis, 2nd Edition(Coad P, Yourdon E, 1990)的截图

图8-13 来自 Object lifecycles. Modeling the world in states(Shlaer S, Mellor SJ, 1992)的截图
8.1.6 互联网和敏捷的影响
互联网浪潮以及敏捷运动的冲击打断了分析的传承。
互联网浪潮到来之前,软件系统的竞争焦点是功能。
我1997年毕业,先到高校当了一年老师,然后才去软件公司做程序员。第一个参与开发的系统是酒店管理系统。这样的系统用的人不多,服务器一台,每个部门放上一台客户端电脑就差不多了,但功能很多,入住退房、收银、客房,餐饮、娱乐、财务、电话计费、各种报表等等,能不能把领域逻辑理清楚非常关键。
互联网的兴起带来了这样一种系统:这种系统功能很简单,开发这种系统时需要思考的领域逻辑很少,但是这样的系统可以通过互联网让非常多的人使用,问题的关键变成了“如何在大用户量下保持性能”。
典型的例子是1996年出现的hotmail,推出一年多时间就有1200万的用户。hotmail是一个基于web的电子邮件系统,这样的系统,开发出来并没有太大难度,竞争的关键在于有没有背景、有没有钱买基础设施,有没有钱做推广……。
可能有人会说“邮件系统也有逻辑啊!”当然,这同样是一个领域,也有逻辑,但是其中的绝大多数逻辑已经被前人探索得很清楚,甚至有实际的可用组件提供,并不需要web电子邮件系统的开发人员从头思考。
很多开发人员就进入了类似的“互联网公司”,开发或维护类似的系统。因为不需要剖析复杂的领域逻辑,开发人员有没有掌握分析的技能已经无所谓,于是,很多打着“敏捷”旗号的“方法”就在这类公司大行其道,导致软件开发人员的分析能力普遍退步。
***********
经常有人和我说,潘老师,敏捷这一套做工厂管理系统之类的可能不太行,但不得不承认,做互联网很管用噢!
当然管用了!
有个巫医发明了一种治疗方法。他坦言,我这个方法对付癌症可能不太行,但对付感冒很管用噢!你不信,找个感冒患者来!
感冒患者找来了,医生让患者躺在一张绘有八卦图案的方桌上,然后绕着患者绕了八八六十四圈(看到没,他也是有一套方法的!),然后对患者说,回去该吃吃该喝喝,五天之内就好了!
果然,患者好了。

图8-14 电影《破坏之王》截图
***********
给软件开发人员一段文字描述,让他提炼和表达其中的领域概念和关系(通过ER图、类图……甚至口述表达都可以)。基于我在训练班上的体会,能在这个测试中给出合格结果的开发人员占全体开发人员的比例,如果在2000年占百分之x的话,二十年之后的2020年,这个比例是否能占到千分之x都值得怀疑。
随着互联网的成熟,大部分组织都变成了“互联网组织”。以往以“互联网公司”著称的巨头们变成了行业领袖,宣称“我是做互联网的”已经不足以包装自己,必须要对领域深入挖掘了。
但是,开发人员“敏捷”惯了,怎么办呢?还能回得去吗?

图8-15 分析技能下降之后,还能回得去吗
8.1.7 伪创新
于是,就出现了各种伪创新。
有的人(国外国内都有)没有掌握相应技能,也不愿意认真学习已有的知识,凭着一些朦胧的“领悟”,就“发明”了一些“新”方法,这就是伪创新。
软件开发的一些伪创新前些年打的是“敏捷”的旗号,最近几年打的是“领域驱动设计”的旗号。仔细观察,背后的人很多是重叠的。
伪创新,例一
图8-16摘自2017年出版的某本名字中带有“Domain-Driven Design”的书,看起来有点像图8-9,对吧?但是图8-16的内容和绘制于1979年的图8-9比起来,水分要多得多。

图8-16 来自2017年出版的某本名字中带有“Domain-Driven Design”的书的截图
这么大一张图,除了Place Order和Ship Order这两个概念之外,剩下的就是废话刷工作量了。右半边,ShipOrder、Ship-Order、Shipping(咦?怎么没有和左边一样前面加个Order叫Order-Shipping呢,这样还可以多几个字母刷工作量)、OrderShipped,这是在上英语语法课吗?
相当于把2个概念刷了4倍工作量,得到2×4=8个结果。
信息浓度=2/8×100%=25%。
从图8-16的表示规律可以看出来,方框是workflow,进入箭头是command,出去箭头是event。既然如此,每个标签文字后面其实可以不用加“workflow”、“command”、“event”等字样,但是,不加怎么显得我工作量大呢?
考虑到这一点,信息浓度估计20%吧。或者反过来说,一条信息刷到5倍。
图8-16还有一个问题,混合了非核心域的知识,会造成之前说的a×b×c,具体在什么地方,留给读者观察。
伪创新,例二
图8-17摘自2019年出版的另外一本名字中带有“Domain-Driven Design”的书。展示的就是打着“领域驱动设计”旗号的伪创新之一:事件风暴(EventStorming)。

图8-17 来自2019年出版的某本名字中带有“Domain-Driven Design”的书的截图
我把图8-17里提到的概念提炼出来,画了1个类和4个小人,如图8-18。数一数,包括类名称在内,图8-18一共有16个概念。

8-18 我提炼图8-17的概念画的图
有了图8-18,可以准备开车……不,准备刷工作量了!
(1)创建对象,销毁对象,刷2个蓝色纸片,就是图8-17中的Create an ad和Remove ad(怎么前面没有an了,刷得不整齐,重刷!)。
这个步骤刷出2个蓝色纸片。
(2)多重性为1的属性(从图8-17看应该是title、text和sell price),每个刷1个蓝色纸片,就是图8-17中的Change the ad title(怎么不和后面两个一致都用Update,刷得不整齐,重刷!)、Update the ad text和Update ad sell price(怎么前面没有the了,刷得不整齐,重刷!)。
这个步骤刷出3×1=3个蓝色纸片。
另外,本来这些都是Ad的属性,直接称title、text和sell price即可,不必再加前缀,但不加怎么能刷出工作量呢?一定要加!
(3)多重性为多的属性(从图8-17看应该是picture和category),每个刷2个蓝色纸片,Add***和Remove***。
这个步骤刷出2×2=4个蓝色纸片。
另外,本来这些都是Ad的属性,图8-17中写Add***和Remove***即可,不用加to Ad、from Ad,但不加怎么能刷出工作量呢?一定要加!
(4)每个操作刷1个蓝色纸片。
这个步骤刷出6×1=6个蓝色纸片。
咦?这些改变状态的操作看着怎么和属性没有什么关系呢?是属性漏了,还是操作错了?估计作者也不太了解操作、状态和属性的关系吧。
(5)把(1)-(4)步产出的所有的蓝色纸片变换词序,每个旁边加一个橙色纸片。
这个步骤结束后,得到(2+3+4+6)×2=30个方框形状的纸片,或者说,15对。
(6)把图8-16中的4个小人和每对方框任意组合,得到大约15个黄色小人。
最终,我们从往墙上贴了30+15=45张小纸片,数量和内容正好和图8-17中的纸片相同。
信息浓度=16/45×100%=36%。再考虑到那些刷上去的Ad,估计差不多33%的浓度。或者反过来说,一条信息刷到3倍。
要注意,这仅仅是其中一个类Ad,其他类照此办理,今年的工作量可算是有交代了。
是不是创始人英明神武,只不过其他人把经念歪了?感兴趣者可以去自行看“事件风暴”的作者Alberto Brandolini的书,看看书里面讲了什么。
*调查:您看过的以“领域驱动设计”为名的文章,有类似的刷工作量的情况吗?欢迎在本文下留言。*
这些伪创新在思想上都有共同的错误:一一对应,内外不分。
世界之所以复杂,或者说,系统之所以复杂,就是因为很多关系不是一一对应的。
组织的一个流程可能由多个系统(包括人肉系统和非人信息系统)协作完成,一个系统可以参与组织的多个流程;系统的一个用例(如果读者没有掌握上册讲解的用例的知识,就当作是功能吧)可能由系统的多个类协作完成,一个类可以参与系统的多个用例。类的一个操作可能会影响多个属性,一个属性可能会被多个操作影响……
正是因为如此,才需要软件开发人员大脑来找出最佳的映射方案,这才是人的脑力需要花费的地方。
而这种思考是有一定门槛的,不是所有人都能胜任。
如果一个人不能胜任,而又不愿意花时间去学习,当有一种“一一对应刷工作量”的伪创新出现在他面前时,自然而然就会产生一种虚幻的“受用”感觉,欢快地投入伪创新的怀抱——
“哥也是有方法的人了!”
最近几年的微服务浪潮中,类似“以用例为依据分割系统”甚至“以业务流程为依据分割系统”等明显内外不分的言论为什么能流传开,就是因为足够简单,方便一一对应刷工作量。
***********
初中数学里要学习全等三角形、相似三角形、SSS、SAS……,到了高中以后学了正弦定理、余弦定理等解三角形的知识……就不会再回去用初中的方法解题了。
但是,不是所有人都能学会高中的知识,比如说张三。
张三可能会这样解释:
“我这个人能力比较弱,只能掌握全等三角形、相似三角形的方法。”
这样的说法没有问题。
张三还可能会这样解释:
“这个题目比较简单,用全等三角形、相似三角形的方法做足够了,而且这样更方便广大人民群众理解。”
这样的说法也可以。不过,竞争对手不是傻子,市场中哪里有什么"简单题目"!能带来利润的题目都很复杂。
但是,张三如果这样说:
“全等三角形、相似三角形的知识比高中三角函数的知识更深刻。”
这就是自欺欺人了。
更要警惕的是,有一个李四,也许和张三一样没有掌握高中方法,也许掌握了高中方法但是为了忽悠张三们,偷偷把"全等三角形"改名为"叠合三角形",然后和张三宣传:
“我发明了"叠合三角形"新方法,比高中的三角函数有用,三角函数过时了。”
这就是可恶了。
***********
回到前面举的伪创新例子。如果说熟练掌握类图、状态机图等建模技能,并发现了其中的缺点,站在前人的肩膀上创新,这完全可以。
在不了解已有知识的情况下,拍脑袋搞出伪创新,甚至向大众宣传伪创新,也是个人自由。
但是,宣传销伪创新时,像上面李四那样胡说“我这个方法比***好”,就不对了。
事实上,一旦付出努力,咬咬牙掌握了更严谨和更高效的方法,是羞于再回头去使用那些打着“敏捷”或“领域驱动设计”旗号的伪创新的。
8.1.8 本书使用的分析方法
待续……
